CISC352_Quiz2复习笔记
Week4
Minimax
Types of Games
General Games
Agents具有独立的效用(utilities)
- 合作、冷漠、竞争等都是可能的
- 我们不让AI独自地行动,它应当
- a) 与人协同工作
- b) 帮助人类
- 这意味着每个AI agents理都需要解决game
Zero-Sum Games
-
Agents具有相反的效用(utility)(即对结果的价值)
- A 觉得越好,B 就越坏
-
让我们设想一个单一的数值,一个代理最大化(maximizes)而另一个最小化(minimizes)
- 可以把结果用一个分数/价值表示:A 想把它变大,B 想把它变小。
-
对抗性的(Adversarial,),纯竞争(competition)
Deterministic Games with Terminal Utilities
-
Many possible formalizations, one is:
-
States: S (start at [s_0])(状态集合,起点 [s_0])
-
[S] 是所有可能局面的集合。
[s_0] 是初始状态(开局棋盘、初始位置等)。
-
-
Players: P={1…N} (usually take turns)(玩家集合,通常轮流走)回合制)
- 有 [N] 个玩家。
- 在两人对抗里就是 [P={1,2}]。
-
Actions: A (may depend on player / state 动作集合,可能依赖玩家/状态)
- [A] 是所有可能动作的集合。
-
Transition Function(状态转移函数): [S×A → S]
-
给定当前状态 [s] 和动作 [a],下一状态 [s’ = T(s,a)] 是确定的
例子(迷宫/吃豆人)
- 状态 [s]:(玩家位置= (2,3),豆子剩余集合=…, 得分=…)
- 动作 [a]:Right
- 转移 [T(s,a)]:
- 如果右边不是墙:位置变成 (2,4),如果那里有豆子就把豆子从集合里删掉、得分+1
- 如果右边是墙:位置保持 (2,3),其他不变
这就是“给定 [s] 和 [a],下一状态完全由规则唯一决定”。
-
-
Terminal Test: [S → {t,f}]
- 终止判断函数:输入一个状态 [s],返回 true/false(结束/没结束)。
-
Terminal Utilities: [S×P → R]
- 终局效用(终局得分):给定终局状态 [s] 和玩家 [p],返回玩家 [p] 在这个终局的收益/分数。
-
Single-Agent Trees
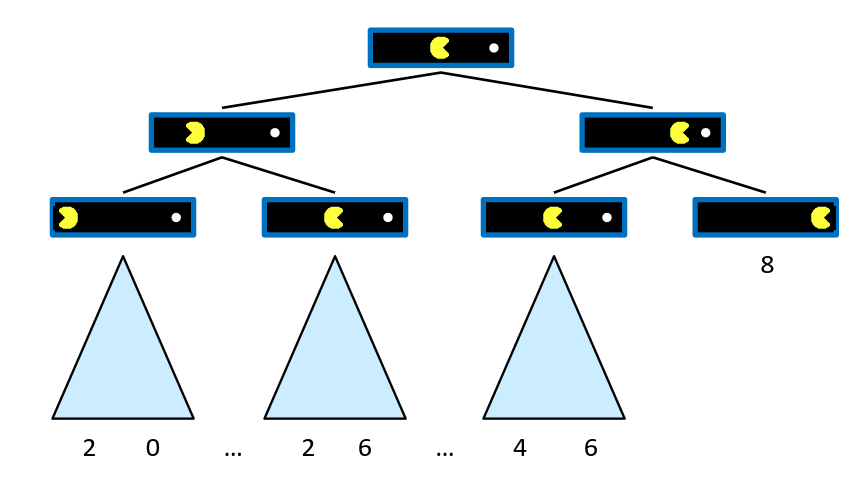
Value of a State
状态的价值[V(s)]
- 从该状态出发,在你采取最优行动的前提下,最终能达到的最好结果(utility)
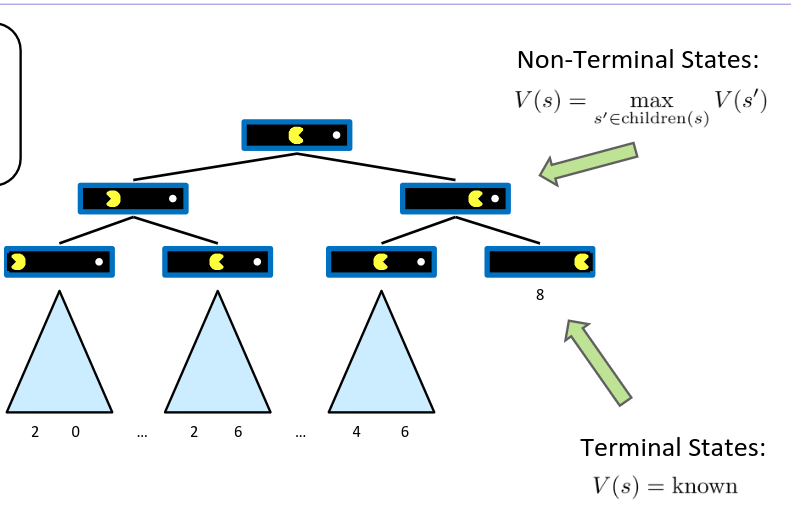
Non-terminal states(非终止状态):
用孩子节点的最大值递推
含义是:
- children(s):从 [s] 出发一步能到达的所有下一状态集合
- 你会选择让最终结果最好的那条路,所以取最大值(max)
Terminal States:
[V(s)]= known
意思是:如果 [s] 是终局(游戏结束),那价值直接由终局效用给出,比如:
- 赢:+1,输:-1,平:0
- 或 Pacman 结算分数:8 分、20 分等
所以叶子节点(终局)上的数值是“已知的”。
Minimax Values
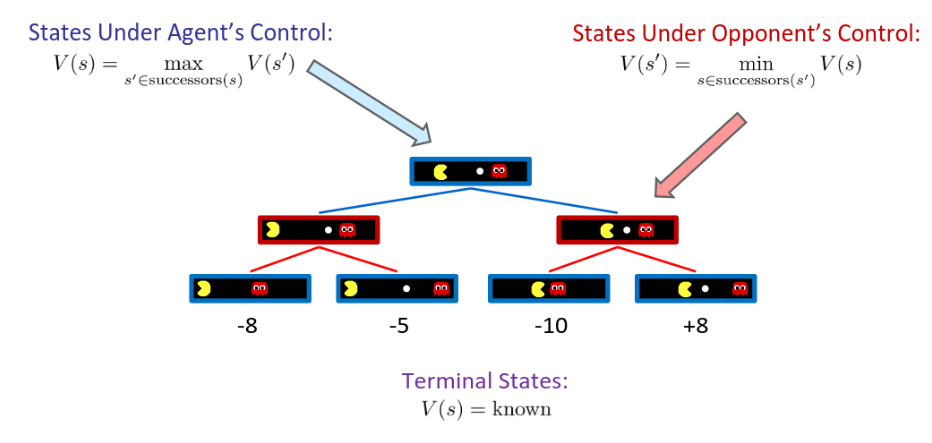
**轮到你(Agent / MAX)**的状态:你会选让自己结局最好的那一步 → 取 max
**轮到对手(Opponent / MIN)**的状态:对手会选让你结局最差的那一步 → 取 min
**终局(Terminal)**的状态:价值已知(叶子上的分数)
Adversarial Search (Minimax)
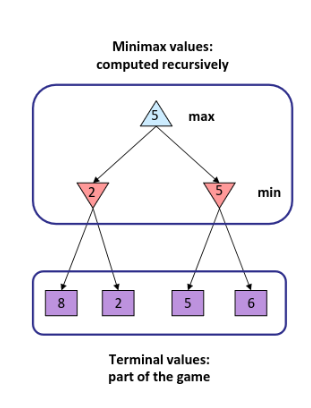
Deterministic, zero-sum games
- 井字棋、国际象棋、跳棋
- 一名玩家使结果最大化
- 另一名玩家使结果最小化
- 并且满足:
- 一个玩家 最大化(maximizes) 结果
- 另一个玩家 最小化(minimizes) 结果
Minimax search
-
建一棵 状态空间搜索树(state-space search tree)
- 节点是局面(state),边是走法(action)。
-
玩家 轮流行动(alternate turns)
- 所以树的层会交替出现 MAX 层 / MIN 层。
-
计算每个节点的 minimax value:
- “面对理性(最优)的对手,从这个局面出发你最终能保证得到的最好效用(best achievable utility)”。
minimax value 不是“对手犯错时我能拿多少”,而是“对手不犯错时我还能保证多少”。
Minimax Implementation
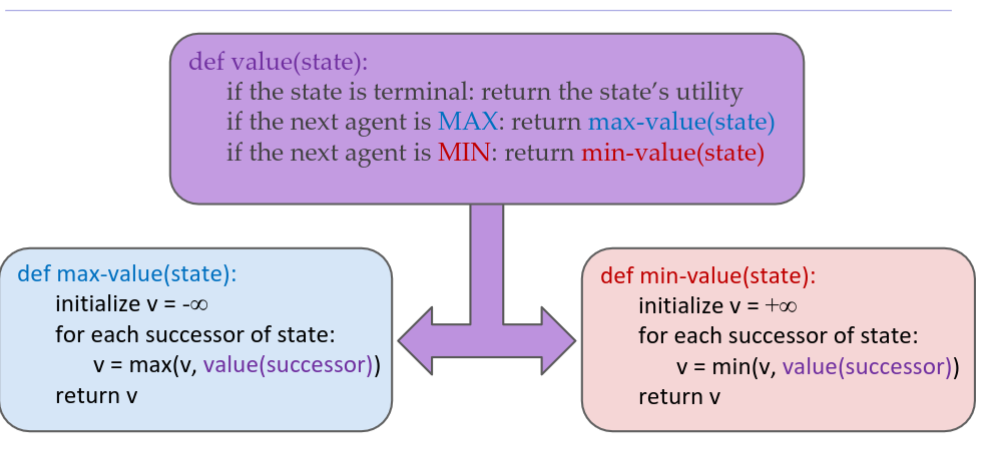
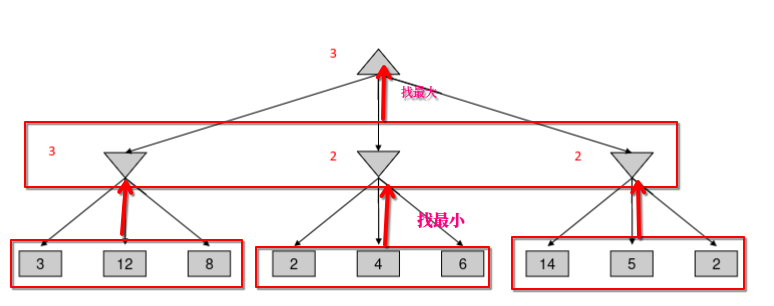
Minimax Example
Minimax Efficiency
How efficient is minimax?
-
Just like (exhaustive) DFS
-
Time: O(bm)
-
Space: O(bm)
-
Example: For chess, b 35, m 100
- 精确解(Exact solution)完全不可行
- But, do we need to explore the whole
tree?- 不需要
- 常见做法包括:
- α–β 剪枝(Alpha-Beta Pruning)
- Resource Limits
- α–β 剪枝(Alpha-Beta Pruning)
- 常见做法包括:
- 不需要
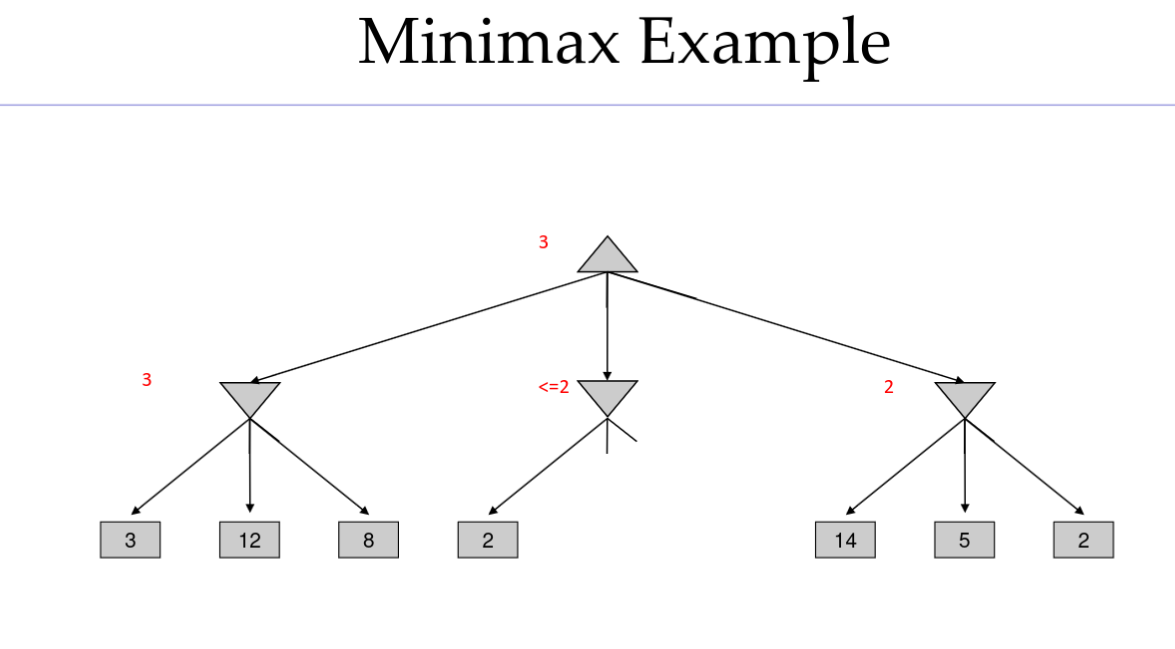
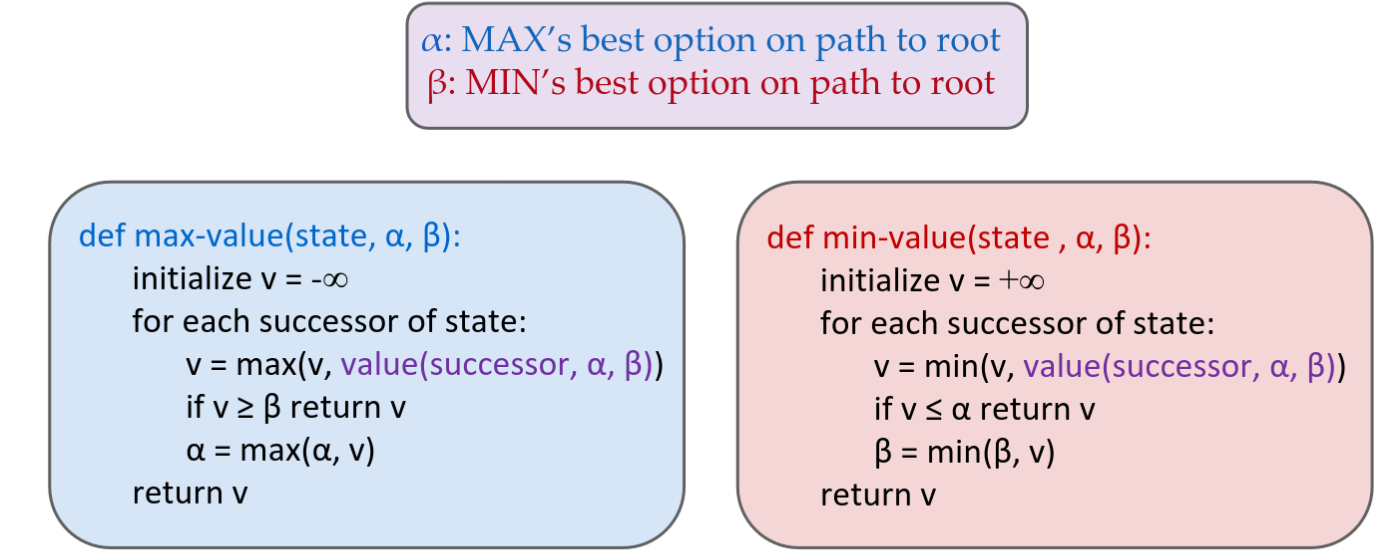
Alpha-Beta Pruning
【【人工智能导论 CS188 2018】伯克利—中英字幕】 【精准空降到 47:33】 https://www.bilibili.com/video/BV1HcqpYwEw6/?p=6&share_source=copy_web&vd_source=65999fb5a6a1ea0570d51832e0dd8b9e&t=2853
通用配置(MIN 版本)
- 当我们正在计算某个节点 n 的最小值(MIN-VALUE)
- 我们正在遍历 n 的子节点
- n 对children节点d的最小值估计会不断下降
- 如果 n 变得比 a 更差,MAX 将会避开它,因此我们可以停止考虑 n 的其他子节点(它已经足够差了,以至于不会被选中执行)
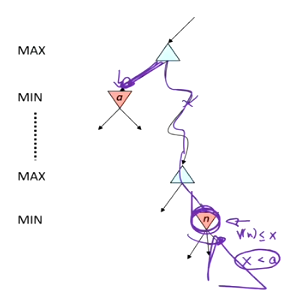
例:
V(n)[\leq]x, x<a
x是遍历n的子节点a得到的值
满足x<a则剪枝
Alpha-Beta Implementation
Alpha-Beta Pruning Properties(剪枝特性)
-
剪枝不会改变根节点的 minimax 最终值
- 因为我们跳过的部分,无论其值如何,都不会影响最终结果,所以最终得到的值是一样的。
-
被剪枝影响的中间节点,它们的数值可能不是精确 minimax 值(只是一种“足够用的界/近似”)
-
因为 α–β 的剪枝条件本质是:
-
在 MIN 节点:一旦当前最小值 ,立刻停止继续看其它孩子(剪枝)。
-
在 MAX 节点:一旦当前最大值 ,立刻停止继续看其它孩子(剪枝)。
注意:停止时,你只看了“部分孩子”。那这个节点真正的 min/max 可能还会被其它没看的孩子改变——你只是没必要知道而已。
-
-
-
子节点展开顺序越好,剪枝越狠。
对于完美排序
- 复杂度:[O(b^{m/2})]
- m:游戏结束前的移动次数
- 使可解深度翻倍!
- 例如,对国际象棋进行完全搜索仍然是无望的。
这是一个关于元推理(metareasoning)(计算关于计算的内容)的简单例子
Resource Limits
现实游戏里算力/时间有限,Minimax(就算加了 α–β)也不可能一直搜到“叶子”(终局)
解决方法:使用DFS
只搜到固定深度 d(比如 6、8、12 ply),就停。
- “Instead, search only to a limited depth in the tree”
不再追求到终局,只展开到深度 d。 - “Replace terminal utilities with an evaluation function for non-terminal positions”
到深度 d 的那些节点大多还不是终局(non-terminal),没有真正的“胜负收益”。
于是用一个评估函数(Evaluation Functions) [Eval(s)] 来估计这个局面对 MAX 有多好:
Example
-
假设我们有 100 秒时间,每秒可以探索 1 万个节点
-
因此每步棋可以检查 100 万个节点
-
α-β 剪枝算法可以达到约 8 层的深度 —— 这是一个相当不错的国际象棋程序
-
不再保证最优解
-
增加搜索层数会产生巨大差异
-
使用迭代加深作为随时算法
- 先设定2层如果还有时间再继续第3层…
Depth Matters深度至关重要
评估函数总是不完美的。
你把评估函数“埋得越深”(搜索深度越大),评估函数本身的质量就越不重要。
这是**特征复杂性(complexity of features)与计算复杂性(complexity of computation)**之间权衡的一个重要例子。
-
方案 A:复杂评估函数(特征多、计算重)
-
优点:每个叶子评估更“聪明”
-
缺点:每次评估更慢 → 你在同样时间里能搜索的节点更少 → 深度可能上不去
-
-
方案 B:简单评估函数(特征少、计算快)
-
优点:单次评估很快 → 能搜索更多节点/更深层 → 靠深度弥补评估误差
-
缺点:局部判断可能粗糙
-
Evaluation Functions
例如我们对国际象棋设定评估函数
-
在深度限制搜索里,你只搜到深度 [d]就停,此时到达的节点大多还是非终局(non-terminal)
-
理想函数:返回位置的实际极大极小值
-
实际应用中:通常是特征的加权线性组合:
[f_i(s)]:从局面 s 计算出来的第 i 个特征值(比如子力差、王安全评分等)如:[f_1(s)]=(# white queens – # black queens), etc.
[w_i]:这个特征的重要程度(权重)
Why Pacman Starves
【【人工智能导论 CS188 2018】伯克利—中英字幕】 【精准空降到 1:12:00】 https://www.bilibili.com/video/BV1HcqpYwEw6/?p=6&share_source=copy_web&vd_source=65999fb5a6a1ea0570d51832e0dd8b9e&t=4320
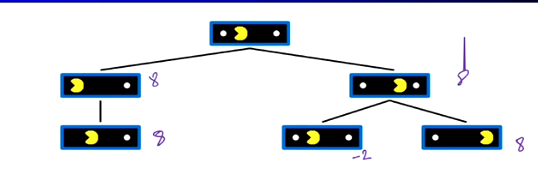
选左和选右都是8一样好
问题在于:评估函数仅通过观察两步后的得分,我们的评估函数并不能很好地反映出当前局势的好坏。
重新审视这张图我们发现左边明显比右边好
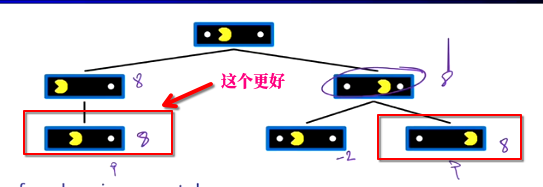
因为你在向目标前进方面已经取得了进展。我们应当在这种情况给予加分如:加一分
总结:改进评估函数来解决
Introduction to Planning
什么是Planning
Planning is the art and practice of thinking before acting.
规划是行动前思考的艺术与实践。 – P@trik Haslum
Types of Planning
确定性(Determinism)
描述行动之后世界状态如何变化、是否有随机性。
- 确定性(Deterministic):同样的状态 + 同样的动作 → 结果必然相同
- 例:棋类(理想化的国际象棋/围棋)、确定性的路径规划
- 非确定性(Non-deterministic):同样动作可能导致多种结果,但不一定给出概率
- 例:机器人抓取可能“成功/失败”,但不知道各自概率
- 概率性(Probabilistic / Stochastic):同样动作的不同结果带概率分布
- 例:移动机器人有 90% 到达目标格、10% 打滑偏移;MDP 常用这一类
可观测性(Observability)
描述智能体能否完全知道当前真实状态。
- 完全可观测(Full observability):能直接看到/测到完整状态
- 例:棋盘信息完全公开的棋类
- 部分可观测(Partial observability):只能看到状态的一部分,需要“信念/估计”
- 例:机器人只靠局部传感器;扑克牌看不到对手手牌(POMDP 常用)
- (有时也会写)概率性观测(Probabilistic observation):观测带噪声、同一状态可能观测到不同值并有概率
- 例:传感器测距有误差分布
多智能体(Multi-agent)
描述参与决策的主体数量以及互动关系。
- 单智能体(Single agent):只有一个决策者,环境不“对抗性”地反应
- 对抗(Adversarial):其他智能体与你目标冲突(博弈)
- 例:对弈、攻防对抗
- 协作(Collaborative / Cooperative):多个智能体共享目标、合作完成任务
- 例:多机器人协同搬运
- 混合(Hybrid):既有合作也有竞争
- 例:团队对抗、市场竞价中既合作又竞争的场景
目标形式(Objective)
描述“好”的定义是什么,也就是优化/规划的评价标准。
- 目标达成(Goal-oriented):只关心是否达到目标(可带最短步数等)
- 例:从起点走到终点即可
- 最小代价(Min-cost):每一步有成本,目标是在约束下让总代价最小
- 例:最短路/最少能耗
- 净收益(Net benefit):收益 − 成本最大化(或期望回报最大)
- 例:带奖励函数的序列决策
- 偏好(Preferences):不一定能用单一数值表示,可能是排序、软约束、层级偏好等
- 例:优先“安全”,其次“快”,再其次“省电”
Planning Formalism
STRIPS
Stanford Research Institute Problem Solver斯坦福研究所问题求解器
The Language
<F, A, I, G>
F: The set of fluents. -> true/false
A: The set of actions. ->智能体可以执行的动作/操作集合
-
Every action a in A is defined using:
o PRE(a): The set of fluents that must hold to execute a 执行动作 a 必须满足的 fluent 集合 o DEL(a): The set of fluents removed from the state执行动作后,要从状态里“删掉”的 fluent(变成 false) o ADD(a): The set of fluents added to the state执行动作后,要加入状态的 fluent(变成 true) o c(a): The cost of executing action a执行动作的成本/代价
I: The initial state->一开始哪些 fluent 为真
G: The goal state->你希望最终满足的条件(哪些 fluent 需要为真)
例子:
Fluents: (connected L1), (link L1 R4), (colour L1 purple), …
Actions: (connect L2 R2), (turn_on), …
Initial State: (power_off), (colour L3 red), …
Goal State: (power_on)
Action Definition
State is represented as the set of fluents currently true
状态 = 当前为真的 fluents(事实)的集合。
-
完整状态(Complete state):假定所有其他流项为假
例如:
F = {At(A), At(B), Holding(X)}
如果当前状态是:
S = {At(A), Holding(X)}
那就表示:
- At(A) = true
- Holding(X) = true
- At(B) = false(因为没列出来)
-
部分状态(Partial state):其他 fluents 真或假都无所谓
例如:
Goal = {At(Box, Room2)}
你只关心这个条件是否满足,其他事实不重要。
PRE(a):前置条件
在 STRIPS 中,每个动作 a 由四部分组成:
-
PRE(a):前置条件
-
执行动作 a 之前必须为真的 fluents
-
形式:PRE(a) ⊆ F
1
2
3
4Move(A, B)
PRE = {At(A), Connected(A, B)}
你必须在 A且 A 和 B 必须连通,否则不能执行这个动作。
-
-
DEL(a):删除列表
-
执行动作后要“变成 false”的 fluents
1
2
3Move(A, B)
DEL = {At(A)}
执行后你就不在 A 了
-
-
ADD(a):添加列表
- 执行动作后要“变成 true”的 fluents
1
2
3Move(A, B)
ADD = {At(B)}
执行后你在 B -
c(a):动作代价
- 执行该动作的成本
1
例如:每步移动 cost = 1或不同动作成本不同
Action Applicability动作可应用性
在状态 s 里,能不能执行动作 a?
动作 a 的所有前置条件,必须都在当前状态 s 里为真。
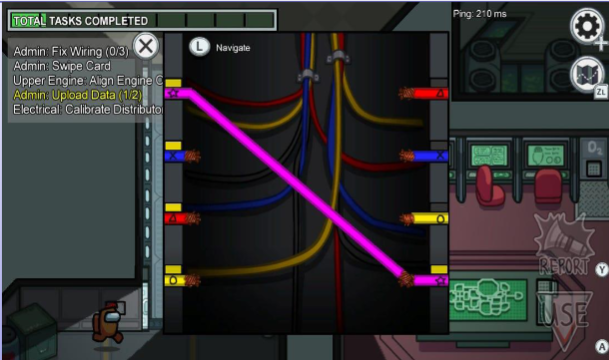
1 | PRE((turn_on)) ={(connected R1), (connected R2),(connected R3), (connected R4)} |
要执行 turn_on(开电源)这个动作:
- R1 要连好
- R2 要连好
- R3 要连好
- R4 要连好
如果有一根线没接好 就不能“turn_on”
Progression
当我们在状态 [s] 执行动作 [a] 时,会发生什么?
- 从当前状态 s 中删除 DEL(a) 里的事实
- 再加入 ADD(a) 里的事实
- 得到新状态 s’
1 | DEL(turn_on) = { power_off } |
什么时候规划结束(Goal Test)
如果目标集合 G 中的所有事实,都在当前状态 s 里为真, 那我们就“完成了”
假设目标:
当前状态:
检查:
- power_on 在 s 里 ✅
因此:规划成功
Week 5
Modelling Planning
- PDDL: 是一种用于描述规划问题的通用语言。
- 类 Lisp 的语法(所以有很多 (((括号!))))
- 存在多种扩展
- 由多种规划器支持
- 由每两年(左右)一次的国际规划竞赛(IPC)推动
PDDL Input Files
规划器需要两个文件:
-
Domain
-
Requirements(需求声明)
- 告诉规划器你使用了哪些语言特性,例如:
(:requirements :strips :typing)
- 告诉规划器你使用了哪些语言特性,例如:
-
Types(类型)
- 定义对象分类,例如:
(:types room robot box)
- 定义对象分类,例如:
-
Predicates(谓词)
-
定义所有可能的“事实”(fluents):
1
2
3
4
5(:predicates
(at ?r - robot ?rm - room)
(connected ?r1 ?r2 - room)
(holding ?r - robot ?b - box)
)
-
-
Actions(动作)
-
定义所有动作:
1
2
3
4
5
6
7(:action move
:parameters (?r - robot ?from ?to - room)
:precondition (and (at ?r ?from)
(connected ?from ?to))
:effect (and (not (at ?r ?from))
(at ?r ?to))
)
-
-
-
Problem
-
Objects(对象)
- 列出具体实体
1
2
3
4(:objects
r1 - robot
room1 room2 - room
) -
Initial State(初始状态)
1
2
3
4
5(:init
(at r1 room1)
(connected room1 room2)
)- 对应 STRIPS 的 I
-
Goal(目标)
1
2
3(:goal
(at r1 room2)
)- 对应 STRIPS 的 G
-
Solving Planning
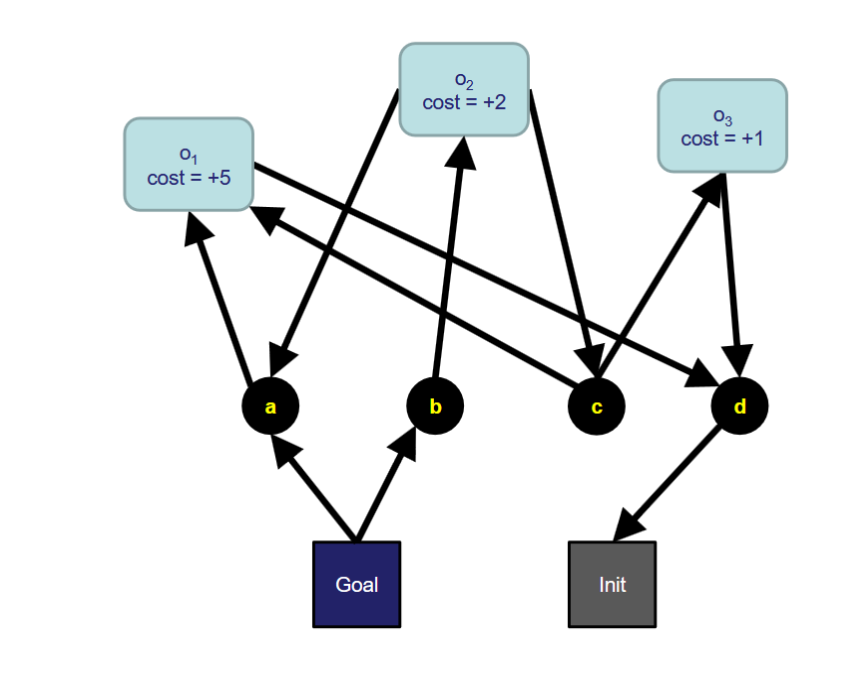
1 | Pre(o1) = {d} |
目标
从 {d} 出发,达到 {a, b},并且总代价最小
h_add 计算
公式:
先算:
所以:
最后算 Goal={a,b}
h_max 计算
公式:
先算:
所以:
再算 Goal
结论
真实最优代价也是 7。
Heuristic Comparison
[h^{add}](加法启发式)
把每个目标子目标的代价 直接相加。
其中 [g(p)] 是达到单个命题 p 的最小代价。
特点
-
Pessimistic(悲观)
- 因为它假设:
- 每个子目标都要 单独花代价去实现
- 不考虑动作可以同时满足多个目标
- 因为它假设:
-
Overestimates true cost 会高估真实代价
-
举个例子:
如果一个动作同时生成 a 和 c,
h_add 会分别计算得到 a 的成本 + 得到 c 的成本,
但实际上只需要执行一次动作。 所以它可能算得比真实代价大
-
-
Inadmissible 不可采纳
-
因为可能:
它会超过真实最优代价。
因此在 A* 中 不保证最优性。
-
h_max(最大值启发式)
-
乐观(Optimistic)
-
因为它假设:
-
达到所有目标的代价
-
只等于最贵的那个目标
-
-
它忽略了其他目标的成本。
- 会低估真实代价
- 因为通常需要实现多个目标, 但它只算一个最大的。
- 可采纳(Admissible)
- 因为永远满足:
所以:可以用于 A*,保证最优解